

Xiaomi has expanded its AI portfolio with MiMo-V2.5, an open-weight model that pushes beyond text-only systems and is designed to handle text, images, and video natively. The company is positioning it as a serious step toward more capable agentic AI, while also making it available through public channels such as Hugging Face, the official API, and AI Studio.
What stands out is not only the model’s openness, but also the performance claims Xiaomi attaches to it. The company says MiMo-V2.5 can compete in demanding areas such as agentic tasks, coding, and visual understanding, all of which have become central benchmarks for modern AI systems.
Built for agentic work
Xiaomi describes MiMo-V2.5 as having “frontier-level agentic capability,” a phrase that points to AI systems able to manage more structured and multi-step tasks. In practical terms, that means the model is not meant only for simple prompts, but also for longer workflows that require planning and coordination.
The company says the model achieved its best internal benchmark results in agentic scenarios. That claim is likely to draw close attention, since agentic performance has become one of the main ways AI models are judged against their peers.
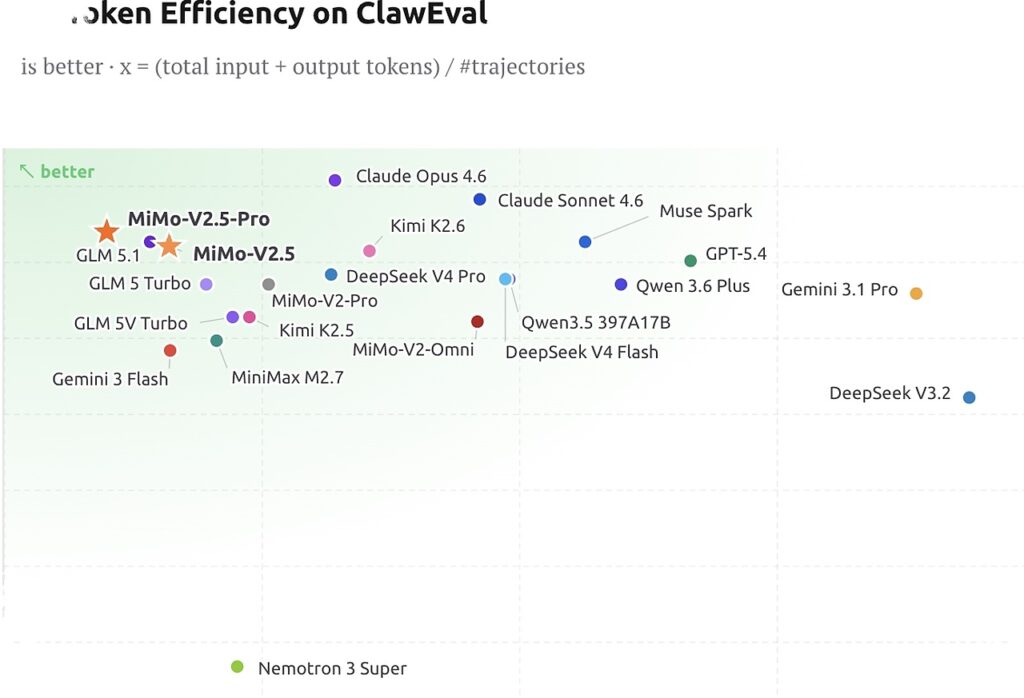
Coding and efficiency are part of the pitch
MiMo-V2.5 is also being presented as a strong performer in coding. Xiaomi highlighted its internal MiMo Coding Bench, where a smaller version is said to match MiMo-V2.5-Pro, despite costing only half as much to run.
That detail suggests Xiaomi is trying to address both capability and efficiency at the same time. For developers, that combination can matter as much as raw performance, especially when systems need to scale across different workloads.
Two versions, two target use cases
The lineup includes two variants with very different sizes. The standard MiMo-V2.5 comes with 310B total parameters and 15B active parameters, while MiMo-V2.5-Pro scales up to 1.02T total parameters and 42B active parameters.
Those numbers show a clear split in strategy. The standard model appears aimed at better efficiency, while the Pro version is designed for heavier computation and more demanding deployments.
Long context and native multimodal design
Another major part of MiMo-V2.5’s design is its 1 million token context window. That allows the model to work with extremely long inputs, which is useful for large documents, extended conversations, and complex multi-part prompts.
Xiaomi also says the model is a native multimodal system rather than one that simply adds visual features later. Text, images, and video are built into the architecture from the start, making multimodal understanding a core part of training and design.
The company says MiMo-V2.5 was trained on 48 trillion tokens. It also claims the model reaches a level on image and video understanding benchmarks that is comparable to closed-source models.
Open access does not mean easy local use
Although MiMo-V2.5 is open-weight, it is not being framed as a lightweight model for everyday consumer hardware. Xiaomi is making it accessible through Hugging Face, its official API, and AI Studio, which broadens access for both users and developers.
Local deployment, however, appears to require very powerful hardware. The source notes that running it on a machine like a high-end Mac Studio is necessary, while consumer GPUs do not have enough VRAM for the task. Even Nvidia’s RTX 5090 is said to fall short for the required local setup.
That gap between openness and hardware demand is likely to shape how the model is used in practice. MiMo-V2.5 may be widely available on paper, but its real-world reach will depend heavily on whether developers can meet the computing requirements needed to run it effectively.
Source: www.gsmarena.com